# 文献网站爬虫工具
Paper Web Crawler,简称PWC。用于爬取文献网站(如IEEE XPLORE、ACM、Springer等)上信息的工具
基于Selenium实现爬虫和XPath分析,绘制表格,并分析发表情况,输出csv以及趋势图等
# 项目地址
仍处于开发阶段,欢迎提交pr和issue!
# 技术栈
- Java
- Web-Http
- GUI
- FreeChart
- Selenium
- Web-XPath
# 项目结构(更新至2021年12月20日)
- bean 各个数据实体
- config 配置包,用于读取配置文件,即
base.yaml - core 核心包,用于调用selenium进行爬虫任务
- gui 图形化包,包装Java可视化图形界面
- log 自定义日志包,链接GUI和爬虫
- param 参数类,包含了各种参数
- util 工具包
# 文献网站的信息提取
selenium可通过XPath获得页面上的信息,XPath是XML文档的一种查询方法, 其基本语法可查看菜鸟教程 (opens new window)
在这里就简单的用一个页面掩饰如何从页面 (opens new window)
中获得想要的信息,打开网页后进入开发者工具 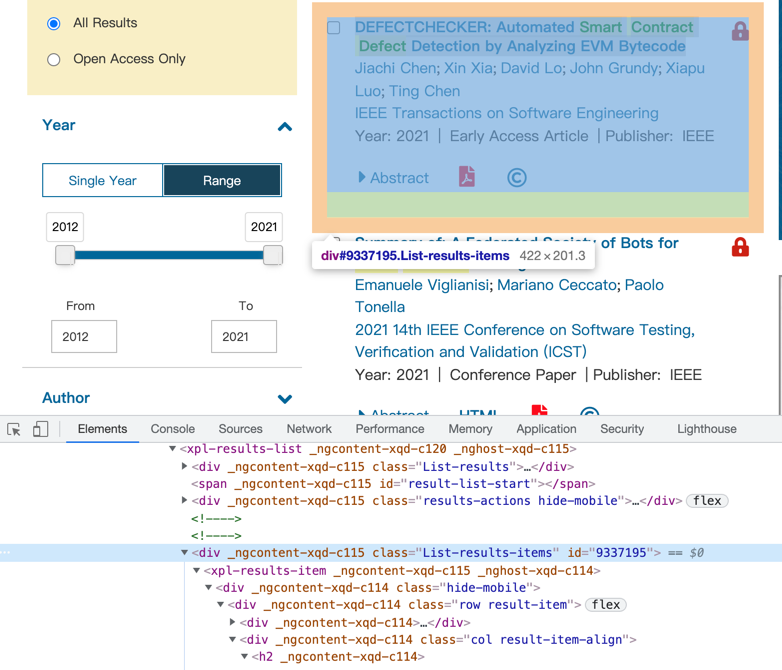 从
从Elements中可以看到,<div> _gncontent-xqd-c115 class="List-results-items" id="9337195">包含了我们想要的信息,那么可以通过如下代码获得该div
标签下的文本内容
webDriver.findElement(By.xpath("//div[@class='List-results-items']")).getText()
1
然而,通过这种方法将获得所有div中包含class为List-results-items的元素的文本。而我们更想要的整个结果列表,因此可以改成以下这段代码
webDriver.findElement(By.xpath("//xpl-search-results//xpl-results-list//div[@id>0]")).getText()
1
这段代码中还是通过限定了id属性大于1,进一步过滤了无用信息,接下来就可以通过文本处理进行信息提取了
# 进阶
以上这种方法是获得了所有可用的信息,在Java中进行文本处理。然而,更科学的方法应该是根据各html标签区分信息类型,通过观察、编写更多的XPath进行信息提取,这样的信息更准确
# 特点
我觉得比较有意思的特点
# 检查更新
(以前觉得检查更新没啥难得,真实现起来确实有点复杂)
利用GitHub release实现检查更新
难点 & 解决方法
| 难点 | 解决方法 |
|---|---|
| 如何知道自己是旧版? | 在GitHub仓库中设置了一个release.json标记最新版本的信息,在base.yaml中标记了自己的版本,通过比较获知自己是否是旧版 |
| 新版如何寻找? | 在release.json中保存着最新的版本的GitHub release地址 |
| 如何下载? | 通过hutool.HttpUtil.downloadFile实现下载 |
| 下载后如何实现更新? | 下载后重命名为pwc_new.exe,提示用户改名 |
← 开源项目